Understanding Recommender Systems
I'd like to think recommender systems as the invisible hand that guides you in exploring "new" stuff that your future you is definitely gonna get without the recsys' help.
Recommenders in general are tools that help us identify worthwhile stuff and they could be any of the following
- Filtering interfaces - e-mail filters
- Recommendation interfaces - suggestion lists like on amazon, top-n, offers and promotions that are more valuable in the enterprise setting
- Prediction interfaces - evaluate candidates, predicted ratings
A little vocabulary
- rating - expression of preference, could either be implicit (inferred from user activity like click, follow, purchase) or explicit (direct from the user like rating, review, vote)
- consumption (right after experiencing), memory (after some time), expectation (not yet experienced)
- prediction - estimate of preference
- recommendation - selected items for user
- content - attributes, text, etc
- collaborative - using data from other users
What are some recommendation approaches?
- Collaborative Filtering
- this is probably the most common approach when it comes to recommender systems. In fact, nowadays, when we say recommender systems, we think collaborative filtering. But of course, this is case to case basis.
- the idea is simple: learn what each person likes, and use information from everyone else in the community to make recommendations
- hence, you are given a matrix of preferences by users per item, and these are then used to predict the "missing" preferences and recommend items with high predictions
- Content-based Filtering
- start by leaning what individuals like, and build a profile to figure out how other items/products match with this profile
- in other words, metadata of items are explored (movie stars, book authors, and music genres)
- Non-personalized and stereotyped based on popularity and group preference
- social and demographic recommenders suggests items that are liked by friends, or friends of friends, or even base on the geographic location of the user
- this approach can be very simple yet powerful, since one does not have to dig deeper into the user profile or the items listed to that user
- Product Association
- not personalized to individuals but pertain to product
In this blogpost, I will be focusing on content-based and collaborative filtering approaches.

A. Content-based filtering approach
Content-based filtering approach works with data that the user provided either explicitly (rating), or implicitly (clicking on an item). Based on this data, a profile is generated, which allows the system to recommend items to the user. Therefore, as the user inputs more and more data, the more accurate the model becomes.
Summary of steps in a nutshell:
- TF-IDF (Term Frequency-Inverse Document Frequency) implementation to convert words to numbers that the computer can crunch
- Cosine Similarity Score (or any other similarity score that could work, like euclidean, Pearson)
- Get top N items
B. Collaborative filtering approach
Collaborative filtering exploits the similarities in behaviors (rating, buying etc) among users by looking into user feedback (ratings). Collaborative filtering approach may either be memory-based or model-based. I'll discuss them in full as we go.
The key difference between memory-based and model-based approach is that there is no learning of parameter involved in memory-based. That is, the closest user or item is calculated using cosine similarity or pearson correlation coefficients, which are generally just based on arithmetic operations.
Memory-based approach
This approach looks into the matrix of preferences of users in terms of items. This matrix is then later on used to predict the missing preferences, and recommends items with high certainty.

Memory-based approach can either be of two types:
- User-based collaborative filtering
"Users who are similar to you also liked..."
To do this, we can use the nearest neighbor algorithm with 2 simple steps
- Find the k-nearest neighbors (KNN) to a certain user using a similarity function.
- Predict the rating that the user might give to all items that its k-nearest neighbors have, that it hasn't rated yet.
Therefore, this involves the User-Item matrix, which we will use to predict the ratings on the items a user has not seen yet, by looking at similar users.
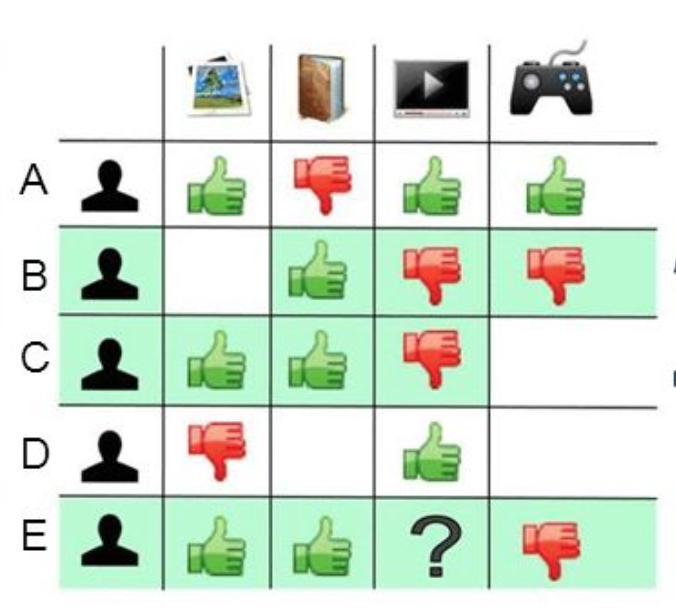
- Item-based collaborative filtering
"Users who liked this item also liked ….."
Now, as opposed to comparing the user with other similar users, we focus on items that are similar to those he likes the most!
To do this new approach, we can do 2 simple steps:
- Calculate similarity among items using any of the following:
- cosine similarity
- correlation-based similarity
- adjusted cosine similarity
- 1-jaccard distance
- Calculate the prediction
- weighted sum
- regression
Item-based approach is usually preferred over the user-based approach because the latter is often harder to scale due to how dynamic the users can be. Items, on the other hand, pretty much stay the same.
To implement the item-based approach, the typical go-to is the KNN (k-nearest neighbor) model. It's a non-parametric lazy learning method.
What's nice about KNN is that it does not assume any underlying distribution in the dataset. KNN first measures the distance from a target item to all the other items in the dataset. Then it ranks all the other items based on their distance from the target, and returns the top k nearest neighbors items.

Model-based approach
Model-based collaborative filtering uses machine learning algorithms to create a model based on training data and then use the model to make predictions
According to this blog, the algorithms in this approach can further be broken down into 3 sub-types.

References:
1. https://medium.com/@cfpinela/recommender-systems-user-based-and-item-based-collaborative-filtering-5d5f375a127f
2. https://heartbeat.fritz.ai/recommender-systems-with-python-part-ii-collaborative-filtering-k-nearest-neighbors-algorithm-c8dcd5fd89b2
3. https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0

Comments
Post a Comment